Manually creating linked clones in vSphere
We’ve started our first “proper” implementation of Linked Clones in our vSphere 4 environment. While we’ve done some limited proof-of-concept work, this is the first project to be entirely deployed using Linked Clones. The objective is to reduce the space used by our training machines on our new environment.
Linked clones allow multiple machines to share a common read-only “base” VMDK file, with each machine generating their own delta (REDO). Under normal usage circumstances, the REDO would continue to grow throughout the life of the machine; however as our machines have non-persistent hard drives, they reset to a clean state when powered-down. This makes our environment ideally suited to taking advantage of the functionality offered by Linked Clones. They can either be created manually (by moving and renaming files on the datastore), or via the APIs, you can get more information on them in this White Paper from VMware.
Our training machines are functionally identical to our production machines, and similarly consist of three types - Capture, Packaging and Verification. These are 11, 8, and 8 GB respectively. The usage patterns are slightly different, as - unlike “live” projects which have a steady stream of work, trainees tend to come in in large batches. This means that the training environment either needs to be continuously large, but mostly idle, or it needs to be regularly redeployed then stripped back.
The benefits achieved via the implementation of Linked Clones in this project resulted in roughly the same ratio of space saving as our proof-of-concepts, but as the number of machines involved was greater, the differences are more pronounced. Also this is the first time we have exceeded 8 machines sharing the same VMDK, which is a notable milestone as it is only possible if we limit the number of possible hosts that the machines can run on (there is a VMFS limitation of 8 hosts accessing a VMDK concurrently). As we have DRS enabled, this meant reducing the number of hosts in each cluster to 8 or less.
We deployed twenty-five machines each, of the three different builds used in a project. All were Windows XP virtual machines
The three machines being used as the parents had their slack space on the drives was cleaned using SDelete, then the machine was converted to Thin Provisioned using Storage vMotion. It was switched off, and a snapshot was created. This snapshot will form the base for the parent’s clones.
The machines were deployed using the a script similar to the one at the bottom of this post, and it took just over an hour to deploy and customize all 75 machines. This was considerably faster than the time it would have taken to deploy 75 machines using the normal “Deploy from template” method.
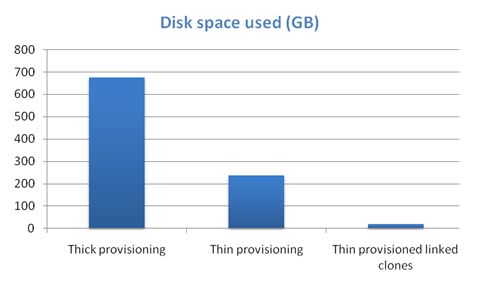
Here are the data:-
- Estimated space used if deployed traditionally: 675 GB- Capture: 11 GB per machine
- Packaging: 8 GB per machine
- Verification: 8 GB per machine
- Estimated Space if Deployed as Thin Provisioned, but not Linked Clones: 238.75 GB- Capture: 3.34 GB per machine
- Packaging: 3.72 GB per machine
- Verification: 2.49 GB per machine
- Space used in current configuration: 19.3 GB- Capture 3.34 GB for parent, plus 0.13 GB per Linked Clone
- Packaging 3.72 GB for parent, plus 0.13 GB per Linked Clone
- Verification 2.49 GB for parent, plus 0.13 GB per Linked Clone
And in graph-format, for extra impact:-
All size estimates are based on the machines in a powered-down state. When powered on, a swap file (equal to the size of the assigned RAM) is created, and (assuming the machines are non-persistent) REDO files are created on all types of machines.
I’ve been on a few of the machines and they don’t appear to suffer from any noticeable performance degradation, although the true test won’t come until we get considerable concurrent use.
I’m tentatively declaring this a huge success. Rather than the training environment using 240 GB between training engagements, it’s now down to a svelte 20 GB, with no reduction in functionality.
Below is a script similar to the one I used to deploy the linked clones. The actual “meat”, which deploys the machines was based on Hal Rottenberg’s New-LinkedClone.ps1 script. As far as possible, I’ve tried to strip out stuff that’s specific to our environment (we use the Custom Attributes as an asset management database and to track which machines were deployed from which templates). There’s probably going to be stuff in there that doesn’t make much sense, but if you’ve got a bit of an understanding of PowerShell, you should be able to cut and keep the bits you want.
# Script to deploy linked clones
# List of custom attributes which you're wanting to copy from the template or parent to the newly created machine
# (Machines deployed from templates no longer inherit CAs in vSphere 4.0)
# These help us track provenance, and provide information to the user
$arrStrAttributesToCopy = @(
"AD Object Location",
"Customisation",
"Infrastructure Consultant",
"Logon Administrator Name",
"Logon Administrator Password",
"Logon User Name",
"Logon User Password",
"Mobilisation Consultant",
"Project",
"Role",
)
# Name of the Custom Attribute on the parent which contains the name of the customisation to use
$CustomFieldName = "Customisation"
function DeployLinkedClone ($strSourceVM, $intToBeDeployed, $intStartDeployingAtNumber, $CustomFieldName){
# Bases the name of the machine on the second part of the string split by spaces. This assumes that the template follows the standard naming convention of "Tmpl [Name] x.x"
$strMachinePrefix = ($strSourceVM.split(' ')[1])
$objVM = Get-VM $strSourceVM
$viewVM = $objVM | Get-View
$objCustomization = Get-OSCustomizationSpec ($objVM.CustomFields.Item($CustomFieldName))
# Ensure that the machines does not have a non persistent HD
if ($objVM | Get-HardDisk | Where-Object {$_.Persistence -like "IndependentNonPersistent"}){
Write-Output -InputObject $objTemplate has a non-persistent HD!
}
# If the customisation, as specified in the parent's custom attribute does not exist, then quit.
if (!$objCustomization){
Write-Output -InputObject Customisation ($objVM.CustomFields.Item($CustomFieldName)) not found. Exiting.
Break
}
$i = 1
Do {
# Convert the single digit integer (i.e., "1") into a double digit (i.e., "01")
$strMachineNumber = ("{0:0#}" -f $intStartDeployingAtNumber)
# Concatenate the machine name prefix (from the template name) with the double-digit integer, which is incrememted on each loop
$strMachineBeingDeployed = $strMachinePrefix+$strMachineNumber
# Check that the machine doesn't already exist
if ((Get-VM -Name $strMachineBeingDeployed -ErrorAction SilentlyContinue)){
Write-Output -InputObject "Machine $strMachineBeingDeployed already exists!"
Break
}
# Let the user know what's going on
Write-Output -InputObject ""
Write-Output -InputObject "Deploying new linked-clone " -NoNewline
Write-Output -InputObject $strMachineBeingDeployed -ForegroundColor Blue -NoNewline
Write-Output -InputObject ", from template " -NoNewline
Write-Output -InputObject $strSourceVM -ForegroundColor Blue -NoNewline
Write-Output -InputObject ", using customisation " -NoNewline
Write-Output -InputObject $objCustomization -ForegroundColor Blue -NoNewline
Write-Output -InputObject ", on the same Host as the parent" -NoNewline
Write-Output -InputObject ""
# Create the new machine using all these variables
$objFolder = $viewVM.parent
$specClone = New-Object Vmware.Vim.VirtualMachineCloneSpec
# Get the most recent snapshot attached to the machine
$specClone.Snapshot = $viewVM.Snapshot.CurrentSnapshot
# Create an object to represent the location of the clone
$specClone.Location = New-Object Vmware.Vim.VirtualMachineRelocateSpec
# This is the move-Type that specifies the new disk backing (which is the bit that makes a linked clone)
$specClone.Location.DiskMoveType = "createNewChildDiskBacking"
# Run the task with the specified parameters
$task = $viewVM.CloneVM_Task($objFolder, $strMachineBeingDeployed, $specClone)
Get-VIObjectByVIView $task | Wait-Task | Out-Null
# Get the object for the machine which was just deployed
$objTargetVM = Get-VM $strMachineBeingDeployed
# Apply the customisation specification to the newly created clone
Set-VM -VM $objTargetVM -OSCustomizationSpec $objCustomization -Confirm:$false
# Start the clone
Start-VM -VM $objTargetVM
# Get the view (needed for writing custom attributes)
$viewTarget = $objTargetVM | Get-View
# Loop through each of the custom attributes which are to be copied
foreach ($arrStrAttributeToCopy in $arrStrAttributesToCopy){
# Read the attribute from the source template
$objAttribute = $objVM.CustomFields.Item($arrStrAttributeToCopy)
# Apply the attribute to the machine object
$viewTarget.setCustomValue($arrStrAttributeToCopy,$objAttribute)
}
# Set the "Template" custom attribute to the parent templates
$arrStrAttributeToCopy = "Template"
$viewTarget.setCustomValue($arrStrAttributeToCopy,$strSourceTemplate)
# Increment the number used for naming the machines
$intStartDeployingAtNumber ++
# Increment the number used to count the number of machines deployed
$i ++
}
# Continue to loop while the number of machines deployed is less than the number required
While ($i -le $intToBeDeployed)
}
# Get the current time (for timing how long the script took to run)
$dteStart = Get-Date
# Name of source VM, should be persistent, should have a snapshot and the customisation specified in the nominated custom attribute
$strSourceVM = "Tmpl Capture 1.0"
# Number to be deployed
$intToBeDeployed = 25
# Number to start deploying from
$intStartDeployingAtNumber = 1
DeployLinkedClone $strSourceVM $intToBeDeployed $intStartDeployingAtNumber $CustomFieldName
# Name of source VM, should be persistent, should have a snapshot and the customisation specified in the nominated custom attribute
$strSourceVM = "Tmpl Packaging 1.0"
# Number to be deployed
$intToBeDeployed = 25
# Number to start deploying from
$intStartDeployingAtNumber = 1
DeployLinkedClone $strSourceVM $intToBeDeployed $intStartDeployingAtNumber $CustomFieldName
# Name of source VM, should be persistent, should have a snapshot and the customisation specified in the nominated custom attribute
$strSourceVM = "Tmpl Verification 1.0"
# Number to be deployed
$intToBeDeployed = 25
# Number to start deploying from
$intStartDeployingAtNumber = 1
DeployLinkedClone $strSourceVM $intToBeDeployed $intStartDeployingAtNumber $CustomFieldName
$dteEnd = Get-Date
$dteDiff = New-TimeSpan $dteStart $dteEnd
$timeTaken = [math]::round($dteDiff.totalMinutes, 2)
Write-Output -InputObject ""
Write-Output -InputObject "It took" $timeTaken "minutes for these machines to deploy"
# End of script